
Naming Things & Separation of Concerns
Some 15 years ago I came across a saying which resonated with me:
There are only two hard things in Computer Science: cache invalidation and naming things.
Phil Karlton
At first, it sounded like a joke, but I felt that it carried some truth. As years have gone by, I now recognize that it actually is quite true. It concisely points out that naming things when coding is tough. Martin Fowler has dug a bit more in the history of this statement.
As developers, we write code that tells a story and has a purpose. The way we code matures over time and becomes very similar to other seasoned programmers. We also develop our individual coding styles which set us apart. However, we find ourselves often asking the questions: “What should I call this?”
We often struggle to find the right word. If English is not our first language, we have even a harder time finding the right word. We explain the code we write to colleagues as we were to tell a story. Classes become actors, while function calls and events become how these actors interact with each other.
Naming things helps us identify the purpose of code. We are akin to librarians, in that we structure code similar to how librarians structure the books in a library.
Separation of Concerns
Separation of Concerns in software development refers to placing related code together. Code with a different purpose is placed in a different class or library.
One of the most common approaches to structure an web application these days is the 3-tier structure, which contains three tiers: API, Services, and Repositories
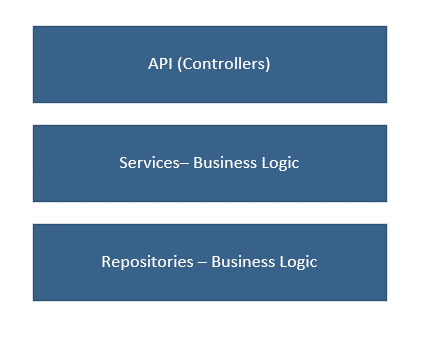
API layer stores our controllers which take input from HTTP requests, and return data back as HTTP responses. In this layer we name classes: UsersController or ProductsController.
Services – store our customization and business logic such as validations, calculations, and logic flow. In the service layer we postfix classes with Service or Validator such as UserService and ProductValidator.
Repositories – store abstractions/classes which represent how data should be stored to a database, cache, or file storage. In this layer we name things UsersRepository or ProductsRepository.
The general consensus appears to arise where we postfix or prefix classes with words which relate to their purpose. We place classes with similar postfixes/prefixes in the same library because they have the same concern.
Naming conventions arise naturally. In our strive for order, we organize our code like a good librarian into classes and libraries, which in turn better separates concerns of our code. We tell stories of imaginary actors (classes or libraries) that behave or react on internal or external events. Over time, we gain even more skills in molding and moving around these actors and their functions, also known as refactoring, but that’s a topic for another post.
Conclusions
- Our code tells a story of actors and interactions.
- Naming classes, variables, and libraries correctly is tough.
- We get better over time in naming things.
- Separation of concerns becomes clearer when we name things correctly.